開場
kubernetes本身架構屬於主從模式(Master/Slave),本篇是第一篇筆記,所以在此先分享並順便紀錄一下,kubernetes裡主從節點如何分工。
Kubernetes中主從節點的功能以及元件
Master Node (Control Plane)
此節點類型為kubernetes集群的大腦,負責容器的調度以及資源的管理,節點內包含以下元件
- kube-apiserver
提供API介面,用於當作集群中各個節點的溝通橋樑,以及接收來自使用者使用API呼叫或者kubectl工具下達的命令,是集群中的關鍵應用,若此元件故障,將導致整個集群無法操作
每個 Node 之間的溝通一定要透過此元件,彼此之間無法直接互相溝通
- etcd
CNCF畢業的專案之一,負責存放整個存放整個集群的狀態及資料的資料庫,也是當集群故障時恢復集群最重要的關鍵
- kube-scheduler
負責集群的資源調配,未指定運行節點的容器將被此元件協調後指派至最符合的Worker Node運行
- kube-controller-manager
負責管理並運行各類kubernetes controller的元件,例如Node Controller、Replication Controller或ServiceAccounts Controller
此元件的操作也都需要仰賴kube-apiserver,必須通過kube-apiserver完成
Worker Node
此節點類型為kubernetes集群的四肢,負責執行容器負載,節點內包含以下元件
- kubelet
Worker Node的管理進程,負責管理此節點上所有Pods的狀態並負責與Master Node溝通
- kube-proxy
負責更新此Woker Node上的iptables,以反映Master Node上service與endpoint的設定,使得流量得以與Pod溝通
- Container Runtime
負責容器的執行,使用符合container runtime interface(CRI)的引擎來執行容器,例如Docker Engine、Containerd以及CRI-O
在此架構上kubernetes集群會有至少一個Master Node(Control Plane)負責容器的調度以及資源的管理,以及至少一個Worker Node負責執行容器負載。
在上述的介紹中,有提到Master Node裡的kube-apiserver元件對整個kubernetes集群至關重要。若集群內只有一個Master Node,那在此Master Node故障時,將失去對整個kubernetes集群的控制,所以希望在集群中有多個Master Node做備援,避免Master Node成為SPOF。
但若集群裡有多個Master Node時,就會需要設定Load Balancer做為單一入口來將控制流量分配到各個Master Node上,並且為了避免Load Balancer本身成為SPOF,此Load Balancer本身也必須處於高可用的狀態。
此篇筆記主要是關於HAProxy與KeepAlived這兩個套件的設定,這兩個套件可以互相搭配來搭建出一套高可用的Load Balancer,並且此套方案已經行之有年,已經可被視為非常成熟可靠的方案。
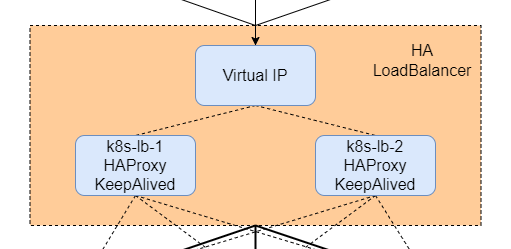
HAProxy與KeepAlived負責的就是整體架構圖中HA LoadBalancer的部分,完整架構圖請參考Kubernetes學習筆記(一) - 起點
介紹與實作
【提醒】架構圖、機器IP列表以及作業系統資訊請參考Kubernetes學習筆記(一) - 起點,本系列一律使用Ubuntu來實作練習
此次示範的HAProxy與KeepAlived版本為
- HA-Proxy version 2.0.13-2ubuntu0.3 2021/08/27
- Keepalived v2.0.19 (10/19,2019)
HAProxy是一個使用C語言編寫的開源軟體,可提供高可用性的負載均衡器功能,以及基於TCP和HTTP的應用程式反向代理功能。
與Nginx一樣,也分為社群版以及企業版,企業版基本上就是多了24*7支援、內建VRRP(等等KeepAlived的部分會講)與RHI(Route Health Injection)等等功能,詳細比較可參考官方網站比較表。基本上社群版已經涵蓋了非常完整的核心功能,這次實作練習完全夠用。
這次會使用HAProxy作為多個Master Node的應用程式反向代理,並且分別在兩台伺服器上,k8s-lb-1與k8s-lb-2,配置一模一樣的HAProxy服務來配合待會要介紹的KeepAlived做高可用備援設定使用。
安裝
sudo apt-get install haproxy -y
|
於終端使用上述指令即可安裝HAProxy
設定
在kubernetes集群中,kube-apiserver預設監聽的端口為6443。
我們需要設定HAProxy監聽6443端口,並將接收到的流量導向我們集群中的多個Master Node的6443端口上,也就是k8s-master-1、k8s-master-2以及k8s-master-3這三台機器上的6443端口。這麼一來當有Master Node故障時,HAProxy可用Master Node上的Health Check Entry未有回應來判斷並自動跳過故障的節點不代理,待節點恢復後才會繼續代理流量。
HAProxy的設定檔的路徑於/etc/haproxy/haproxy.cfg,我們先在k8s-lb-1上編輯此設定檔
以我的環境為例,打開後原設定檔長相如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
daemon
# Default SSL material locations
ca-base /etc/ssl/certs
crt-base /etc/ssl/private
# See: https://ssl-config.mozilla.org/#server=haproxy&server-version=2.0.3&config=intermediate
ssl-default-bind-ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384
ssl-default-bind-ciphersuites TLS_AES_128_GCM_SHA256:TLS_AES_256_GCM_SHA384:TLS_CHACHA20_POLY1305_SHA256
ssl-default-bind-options ssl-min-ver TLSv1.2 no-tls-tickets
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
errorfile 400 /etc/haproxy/errors/400.http
errorfile 403 /etc/haproxy/errors/403.http
errorfile 408 /etc/haproxy/errors/408.http
errorfile 500 /etc/haproxy/errors/500.http
errorfile 502 /etc/haproxy/errors/502.http
errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
|
我們需要在設定檔最後加入應用程式代理設定,加入以下設定並以你自身情況自行修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| # 全域設定區塊
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
daemon
# Default SSL material locations
ca-base /etc/ssl/certs
crt-base /etc/ssl/private
# See: https://ssl-config.mozilla.org/#server=haproxy&server-version=2.0.3&config=intermediate
ssl-default-bind-ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384
ssl-default-bind-ciphersuites TLS_AES_128_GCM_SHA256:TLS_AES_256_GCM_SHA384:TLS_CHACHA20_POLY1305_SHA256
ssl-default-bind-options ssl-min-ver TLSv1.2 no-tls-tickets
# 若設定區塊沒有指定以下設定,則自動套用以下設定
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
errorfile 400 /etc/haproxy/errors/400.http
errorfile 403 /etc/haproxy/errors/403.http
errorfile 408 /etc/haproxy/errors/408.http
errorfile 500 /etc/haproxy/errors/500.http
errorfile 502 /etc/haproxy/errors/502.http
errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
#---------------------------------------------------------------------
# 設定代理入口所使用的監聽端口、代理模式以及配對的後端應用程式代理設定
#---------------------------------------------------------------------
frontend apiserver # 代理入口設定區塊,名為 apiserver
bind *:6443 # 監聽此機器上的 6443 端口當作代理入口
mode tcp # 使用 TCP Layer 4 代理模式
option tcplog # 紀錄 TCP 連接的 Log
default_backend apiserver # 指定後端應用程式代理設定使用名為 apiserver 的設定區塊
#---------------------------------------------------------------------
# 設定後端應用程式代理,以RR循環的方式將請求分配到後端的Master Node上
#---------------------------------------------------------------------
backend apiserver # 後端應用程式代理設定區塊,名為apiserver
mode tcp # 使用 TCP Layer 4 代理模式
option tcplog # 紀錄 TCP 連接的 Log
option ssl-hello-chk # 傳送SSLv3 Hello封包測試SSL連線是否正常
balance roundrobin # 使用 Round Robin 循環的方式分配流量到以下後端清單
# server ${HOST_ID} ${HOST_ADDRESS}:${APISERVER_SRC_PORT} check -- 代理送往的執行個體IP與端口,最後的 check 表示啟用 TCP health check 功能,以自動剔除故障流量
server k8s-master-1 10.0.254.250:6443 check # 換成你練習或正式環境的 Master Node 主機資訊
server k8s-master-2 10.0.254.249:6443 check # 換成你練習或正式環境的 Master Node 主機資訊
server k8s-master-3 10.0.254.248:6443 check # 換成你練習或正式環境的 Master Node 主機資訊
|
再來重啟HAProxy並設定自動啟動
sudo systemctl restart haproxy
|
於終端使用上述指令來重啟HAProxy使設定生效
sudo systemctl enable haproxy
|
於終端使用上述指令來讓HAProxy於開機時自動執行
完成上述動作後,我們可以使用以下指令來檢查HAProxy是否有正確的啟動並監聽在指定的端口上
IP帶入你Load Balancer的IP,端口這邊帶入我們先前設定的6443,成功會顯示succeeded,失敗則顯示failed: Connection refused
圖例:
成功

失敗

當然也可以在裝有HAProxy的主機上使用以上指令來列出系統上所有正在占用監聽的端口,以檢查是否有6443出現
圖例:

同樣在k8s-lb-2主機上建置一模一樣的設定檔,我們就會得到兩台一樣功能與設定的Load Balancer,接下來再配合KeepAlived套件即可實現HAProxy的備援並完成本篇筆記目標。
有了兩台一樣的HAProxy後,接下來就是要解決如何在一台HAProxy故障時,如何使請求自動切換到另外一台好的HAProxy,且使用的IP又不需要特別更換。
KeepAlived是一個基於VRRP(Virtual Router Redundancy Protocol)協議來實現的服務高可用方案,使用C語言編寫的開源軟體,其套件會在多台設定KeepAlived的機器間以權重為依據來推選出一台MASTER,並賦予其MASTER一組Virtual IP。當MASTER不幸當機或Health Check腳本檢查未通過時,其機器上的權重就會因此減少(以Priority值為基準)。當MASTER不再是權重最高者,多台設定KeepAlived的機器間就會重新再選出一台MASTER並賦予同樣的Virtual IP,以達到服務熱備切換的目的,故權重的配置設定正確與否非常重要,配錯的話將導致無法正常進行主從切換,或造成網路上有多個MASTER存在(稱為Split Brain)。
附記,當主備切換時,KeepAlived會傳送GARP(稱為無故ARP或免費ARP)來刷新ARP快取,以將流量正確導向新的MASTER
有了KeepAlived配合HAProxy,就可以讓KeepAlived提供一組虛擬IP,並在兩台HAProxy之間熱備切換,完成高可用性的建置。
安裝
sudo apt-get install keepalived -y
|
於終端使用上述指令即可安裝KeepAlived
設定
KeepAlived的設定檔的存於/etc/keepalived/內,初始資料夾內全空狀態,需要自己創建設定檔。
我們先在k8s-lb-1上編輯此設定檔,創建並編輯/etc/keepalived/keepalived.conf檔案,加入以下設定並以你自身情況自行修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| # Health Check 腳本設定
vrrp_script chk_haproxy { # 新增一個腳本設定區塊,名為chk_haproxy
script "killall -0 haproxy" # 要執行的腳本,可以是sh檔也可以是指令,此處使用killall傳送signal 0來確定進程是否存在,存在將回傳0,不存在則回傳1
interval 2 # 檢測的時間間格,單位為秒
weight 2 # 此腳本作動時的權重值,分為以下情況
# 當 weight > 0
# 腳本回傳值為0時,優先級為 priority + abs(weight),優先級會增加
# 腳本回傳值非0時,優先級不變
# 當 weight < 0
# 腳本回傳值為0時,優先級不變
# 腳本回傳值非0時,優先級為 priority - abs(weight),優先級會減少
}
vrrp_instance haproxy-vip { # 新增一個 VRRP 執行個體設定區塊,名為 haproxy-vip
state MASTER # 初始狀態,若為 MASTER 則為啟用中的伺服器,BACKUP 則為備援伺服器,但實際是誰為 MASTER 主要還是要看權重
priority 101 # 此伺服器的初始優先級, MASTER 的優先級應該要比 BACKUP 還要高,範圍為0~255
interface ens160 # 作用的網路介面卡,可使用 ip add 或 ifconfig 工具查看
virtual_router_id 60 # 識別編號,同一組 KeepAlived 中所有主備伺服器的編號應設定一致
advert_int 1 # 主備伺服器同步檢查間隔,單位為秒
authentication { # 驗證設定,可防止未經授權加入
auth_type PASS
auth_pass k8s-lb@lab # 密碼
}
unicast_src_ip 10.0.254.252 # 單播通告的來源IP,設定為此台伺服器的IP即可
unicast_peer { # 同儕IP,也就是同群組內的其他主備援伺服器IP地址
10.0.254.251 # k8s-lb-2 的IP地址,請視自身情況修改
}
virtual_ipaddress { # KeepAlived 使用的 Virtual IP 地址,請視自身情況修改
10.0.254.253/16 # 這裡我使用之前規劃好,預留的 Virtual IP 地址,請填寫 CIDR 格式
}
track_script { # 設定此 VRRP 個體要執行的 Health Check 腳本,可編寫多個腳本在Priority基準上加減
chk_haproxy
}
}
|
附記,可以使用 sudo killall -0 haproxy;echo $? 命令來觀察killall的回傳值,其中$?為linux的特殊變量,可印出上個執行命令的返回值
關於vrrp_script,官方文檔中也有提出一個基於HTTP Entry來檢測HAProxy服務狀態的腳本,這裡順便紀錄一下,可以參考,這次直接使用進程狀態判斷
1
2
3
4
5
6
7
8
9
10
11
| #!/bin/sh
errorExit() {
echo "*** $*" 1>&2
exit 1
}
curl --silent --max-time 2 --insecure https://localhost:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit "Error GET https://localhost:${APISERVER_DEST_PORT}/"
if ip addr | grep -q ${APISERVER_VIP}; then
curl --silent --max-time 2 --insecure https://${APISERVER_VIP}:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit "Error GET https://${APISERVER_VIP}:${APISERVER_DEST_PORT}/"
fi
|
再來重啟KeepAlived並設定自動啟動
sudo systemctl restart keepalived
|
於終端使用上述指令來重啟KeepAlived使設定生效
sudo systemctl enable keepalived
|
於終端使用上述指令來讓KeepAlived於開機時自動執行
接著,在另一台Load Balancer的主機上,也就是k8s-lb-2,用上面的設定檔做適當的修改並配置KeepAlived,就可以來驗證我們部屬的成果了。
驗證
一開始倘若HAProxy與KeepAlived服務皆正常,就可以觀察到k8s-lb-1的網路介面多了一組IP,也就是上面設定的Virtual IP
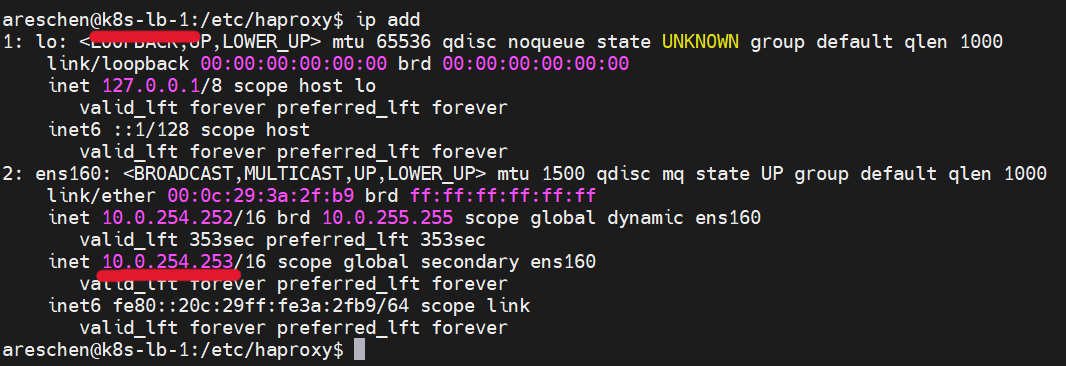
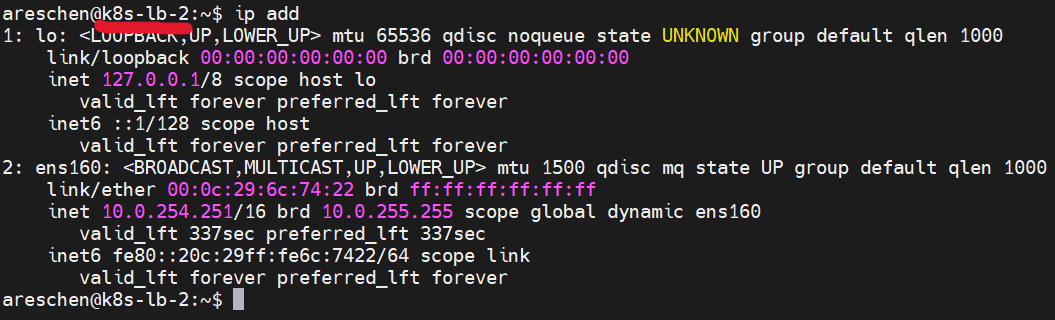
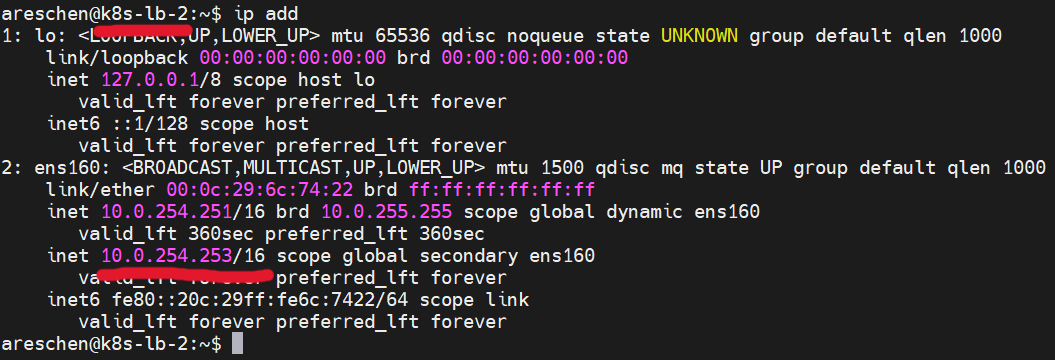
接著,我們將k8s-lb-1上的HAProxy服務停止,可以觀察到一段時間後,因為服務停止造成權重低於k8s-lb-2,Virtual IP就消失在k8s-lb-1主機上,轉而跑到k8s-lb-2的網路介面上了
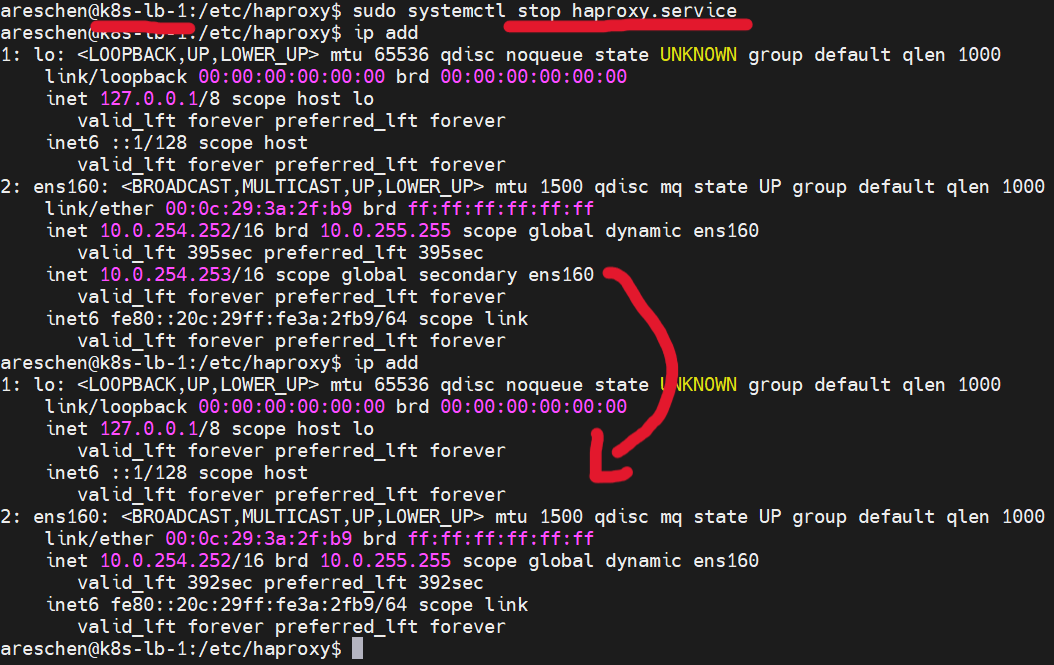
總結
到此我們就成功部屬了一套高可用的Load Balancer,並且有個單一入口可用來將控制流量分配到集群內的多個Master Node上,避免單點故障而失去對集群的控制,下一篇筆記我們就會來正式創建並設定高可用的kubernetes集群。